全国免费咨询热线
13988889999
工作时间:周一到周六 AM8:30
工作时间:周一到周六 AM8:30


CONTACT

时间:2024-03-12 12:04:13 点击量:
置信域在当前最优结果附近定义一个范围,在这个范围内优化目标可以被近似为另一个函数
求解
一般在全空间中迭代产生若干点,是的
越来越小,从
迭代生成
基于两种方法
获得下降方向并将x向着向下方向进行移动,类似于梯度下降
给定一个置信域,求解约束
使用二次方模型近似目标函数,但是如何约束置信域的大小?设置不合适可能导致收敛很慢或者过拟合
考虑的优化问题是Rosenbrock function
全局最优为
解决了置信域大小难以约束的问题,置信域大小根据上一次迭代的表现决定,如果上一次表现存在较大提升,则采取更加激进的优化步长,反之减少优化步长
在处泰勒展开
每一步迭代求解
根据每次迭代的结果确定,先计算预测优化量和实际优化量的比值
说明优化目标与实际优化方向相反,如果
,判断条件(
是置信域的上街)
随后还需要考察模型的提升程度,如果,否则
拉格朗日对偶,假设feasible point是,于是需要满足
其中是正定矩阵(如果f(x)是凸函数的话)
在置信域内,保留泰勒展开的一次项,沿着线性方向优化,首先使用线性项
这里可以看出其实这种方法类似于梯度下降,选择的方向是梯度方向,选择的步长是
将梯度归一化为一个大小为1的向量,
保证步长不超过置信域,选定步长约束为
将包含步长约束的步长带入二次展开中
我们优化的目标是让,这样就得让第二项权重小于第三项(如果第三项权重为正的情况下)
这是一个拟二次函数,全局最优满足,但是全局最优如果不在置信域中时,全局最优和置信域的交点并非一步最优迭代的结果
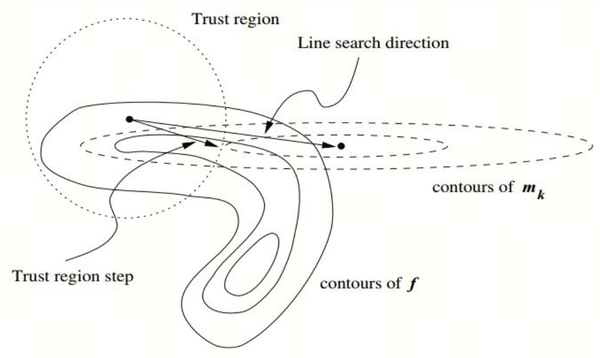
圆圈表示的是置信域,虚线表示的是二次展开的等高线,实线表示的是真实函数的等高线,可以看到Trust Region Step和Line Search direction(指向二次展开的最低点)存在区别,因此需要对Line Search Step进行一些修正
真实的最优步长具有如下特点
使用torch自动求导机制,希望使用GPU增加并行度,比如
a = torch.tensor(1.0,requires_grad = True).cuda()
b = torch.pow(a,2)
b.backward()
print(a.grad)
此时会显示a is not leaf,必须将张量定义写成
a = torch.tensor(1.0,requires_grad=True,device='cuda:0')
梯度是
hessian矩阵是
采取三种方式优化
0,0处的梯度,hessian矩阵
求解最优化问题
对于二项分布(p,N)而言,它的分布函数为
考虑累计分布
希望将其写成简单的形式,对于beta函数,定义(a,b均为整数)
因此累积概率分布写成
生成正态分布
一个随机变量是时间的函数,我们在时间域上进行n次采样,得到n维向量
,如果这个n维向量满足n维高斯分布,那么这是一个高斯过程
如果是标准正态分布,并且n维向量之间独立同分布,那么n维向量满足
一般的情况,如果n维向量并不满足iid,记
分别为向量的期望和协方差,向量满足分布
多元二次分布由均值和协方差函数共同确定,
对于高斯过程时间片上进行采样得到的随机向量
,它满足高维高斯分布
现在在新的时间片,采样得到的一个新随机变量
,加入到原始随机变量向量中满足k+1维高斯分布
机器学习任务希望根据输入的特征向量x预测标签y,我们希望预测标签概率的分布,对于黑盒模型
,只能通过一些采样点
下的采样结果
拟合出这个黑盒函数,记
为采样向量,它满足k维高斯分布
我们希望根据样本值求出正态分布的均值向量和协方差矩阵,协方差矩阵记为
k是核函数,也被称为协方差函数,需要满足
采用高斯核
预测矩阵函数,简单的方法是映射到常数
建模均值向量和协方差矩阵后,可以根据多维正态分布预测在任意点函数值,对于样本值
和采样值
,对于接下来预测的点x对应的函数值
,我们希望预测其数学期望和方差
令,加入到原先的随机变量向量中,变为
,满足k+1维高斯分布
K是先前k次采样的协方差矩阵,计算向量k和协方差矩阵都没有用到函数值
多维高斯分布的条件分布是一维分布
在前k个采样点都确定的情况下,显然是
的函数,贝叶斯优化基于探索-利用权衡最大化
高斯过程回归可以用于拟合非线性模型
对于训练数据集
,给定输入
,求出预测数据Y
K通过核函数得到
黑盒优化问题:函数的表达式位置,无法通过梯度下降方法求得梯度
输入:f(黑盒优化目标),X(参数搜索空间) D(采样得到的数据集) M(对数据集D拟合得到的模型,本文中采用高斯模型) S(采集函数,在参数空间中选择新的采样点,添加到数据集中)
算法:
- 从参数搜索空间中采样获得原始数据集D
- 迭代若干步
- 对于任意输入x,标签y,计算当前数据集下输出产生对应标签的概率
- 根据估算的分布采样新的数据点
- 计算采样点处的函数值
- 将
添加到数据集D中形成新的数据集
关键是根据数据集D推断它的分布和从采集函数获取下一个数据点
计算协方差和均值,输入记为
输入x和输出y之间被建模为正态分布,计算正态分布的参数需要用到高斯过程回归
优化目标
观测值
贝叶斯优化的目标是找到一组序列使得趋近于优化目标,实际上迭代序列中的每一个元素都通过优化另一个优化目标实现
被称为acquisition function,这个函数的选择要容易优化并且足够近似原本优化目标,这里牵涉到探索-利用均衡
使用Gaussian Process建模这一过程,对于已经得到的探索序列,建模其均值
和方差
,分别用于利用和探索
代理函数的作用是给样本点内每个样本打分,代理函数依据之前得到的样本点采样获得
获得(采集)函数根据打分返回最佳的采集样本,新的样本生成新的代理函数
选择的迭代方式是
在迭代时可以看成一个常数
有n个物品
,每个物品具有一个被用户转化的概率p,记作
转化率在推荐系统中可以视为用户的点击
推荐系统中涉及探索-利用问题,对于已经探索得到的点击序列,如果推荐点击过的商品,视为利用,反之视为探索,注意概率对于用户是不可见的,用户只能获得每次饰演的结果
一个机器有k个摇臂,投入一枚硬币,摇下第i个摇臂,返回
奖励,
实际的模型用的是高斯过程回归,给定特征矩阵和标签y,建模高斯过程
调用model.predict(X)获取高斯模型对于样本的预测
定义获得函数为
均值体现出利用,方差体现出探索
定义利用函数
最小化问题中只有不大于
就有奖励,利用函数定义为
实际上对于候选集中每一个采样点x,我们估算的概率(可能比现有结果更优的概率),候选集中每个点的函数值
满足高斯分布
假设满足标准正态分布
,那么
满足均值为
,方差为
的正态分布,利用函数写成
则
结合的形式
由于观测值是一个随机变量,对应的获得函数也是一个随机变量,因此
的大小实际上刻画了
的概率
是标准正态分布,记住
,进一步写成
本文使用 Zhihu On VSCode 创作并发布
地址:海南省海口市玉沙路58号 电话:0898-88889999 手机:13988889999
Copyright © 2012-2018 首页-四方娱乐-注册登录站 ICP备案编:琼ICP备88889999号






