全国免费咨询热线
13988889999
工作时间:周一到周六 AM8:30
工作时间:周一到周六 AM8:30


CONTACT

时间:2024-04-29 04:06:56 点击量:
定义:批量梯度下降法(Batch Gradient Descent,BGD)是最原始的形式,它是指在每一次
迭代时使用所有样本来进行梯度的更新。
优点:一次迭代是对所有样本进行计算,此时利用矩阵进行操作,实现了并行。由全数据集确定的方向能够更好地代表样本总体,从而更准确地朝向极值所在的方向。当目标函数为凸函数时,BGD一定能够得到全局最优。
缺点:当样本数目 m 很大时,每迭代一步都需要对所有样本计算,训练过程会很慢。

定义:一次只对一个样本进行梯度下降,进行参数更新;
优点:由于不是在全部训练数据上的损失函数,而是在每轮迭代中,随机优化某一条训练数据上的损失函数,这样每一轮参数的更新速度大大加快;
缺点:准确度下降。由于即使在目标函数为强凸函数的情况下,SGD仍旧无法做到线性收敛;可能会收敛到局部最优,由于单个样本并不能代表全体样本的趋势;不易于并行实现;
由于是随机梯度下降,下图左上角的同心圆是单样本的loss等值线图,右下角也是和左上角一样都是单样本的等值线图,可以看到如果是SGD的话,梯度下降的方向会出现不稳定,不能线性收敛,即Zigzag现象。

定义:小批量梯度下降(Mini-Batch Gradient Descent, MBGD)是对批量梯度下降以及随
机梯度下降的一个折中办法。其思想是:每次迭代 使用指定个(batch_size)样本来对
参数进行更新。
优点:通过矩阵运算,每次在一个batch上优化神经网络参数并不会比单个数据慢太多。每次使用一个batch可以大大减小收敛所需要的迭代次数,同时可以使收敛到的结果更加接近梯度下降的效果。
缺点:batch_size的不当选择可能会带来一些问题。

全称是: Stochastic Gradient Descent with Momentum,动量随机梯度下降。
为什么提出?
因为使用SGD容易出现Zigzag现象,为了避免出现Zigzag现象,所以有了SGDM方法。
过程:
函数:
f
(
ω
t
)
f(\omega_t)
f(ωt?)
ω
t
+
1
=
ω
t
?
η
t
\omega_{t+1}=\omega_{t}-\eta_t
ωt+1?=ωt??ηt?
η
t
=
α
?
m
t
\eta_t=\alpha \cdot m_t
ηt?=α?mt?,其中
α
\alpha
α是学习率
m
t
=
β
1
?
m
t
?
1
+
(
1
?
β
1
)
?
g
t
m_t=\beta_1\cdot m_{t-1}+(1-\beta_1)\cdot g_t
mt?=β1??mt?1?+(1?β1?)?gt?
其中:
β
1
\beta_1
β1?是动量参数,
m
t
m_t
mt?是累计梯度,
g
t
g_t
gt?是当前梯度
g
t
=
?
f
(
ω
t
)
g_t=
abla f(\omega_t)
gt?=?f(ωt?)
先对
m
t
m_t
mt?的前三项进行展开,

每一项的
m
t
m_t
mt?都包含前面的所有的
g
i
g_i
gi?,使梯度下降的方向的趋于BGD的方向,从而也趋近于我们优化的方向。
下面是关于SGDM为什么是趋近于BGD优化方向的图解,希望能看得懂,
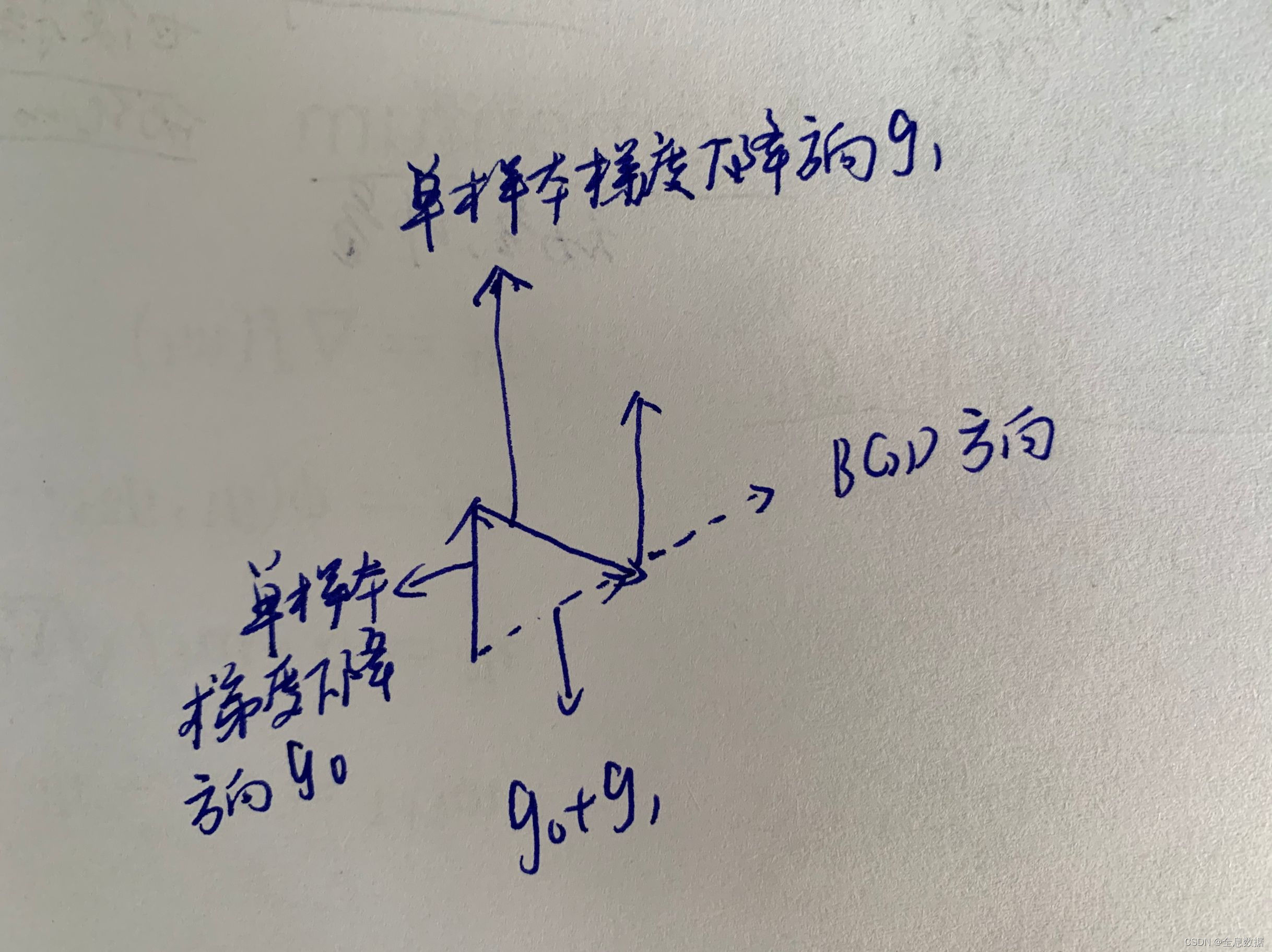
全称为:Nesterov Accelerated Gradient (SGD with Nesterov Acceleration)
这个方法用的比较少,我也没有看懂,就贴一下这个方法的过程吧;

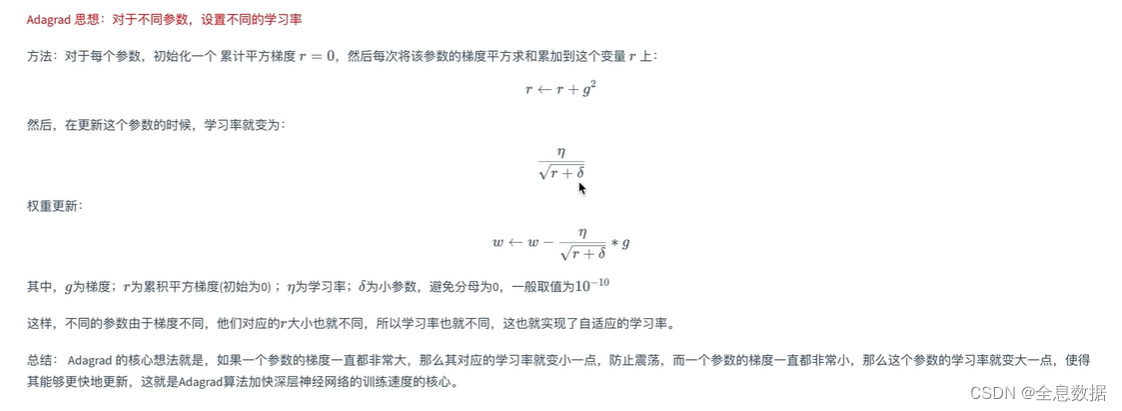
定义:自适应梯度下降,每次梯度下降时会除以前面梯度计算总和的平方再开方;每个参数都有自己独有的学习率
优点:避免前期梯度下降的梯度爆炸和弥散;
缺点:后期有可能会停止训练
V t = ∑ τ = 1 t g τ 2 V_t=\sum_{ au=1}^{t}g_ au^2 Vt?=∑τ=1t?gτ2?
η t = α ? g t / V t \eta_t=\alpha\cdot g_t / \sqrt{V_t} ηt?=α?gt?/Vt??
ω t + 1 = ω t ? η t \omega_{t+1}=\omega_t-\eta_t ωt+1?=ωt??ηt?
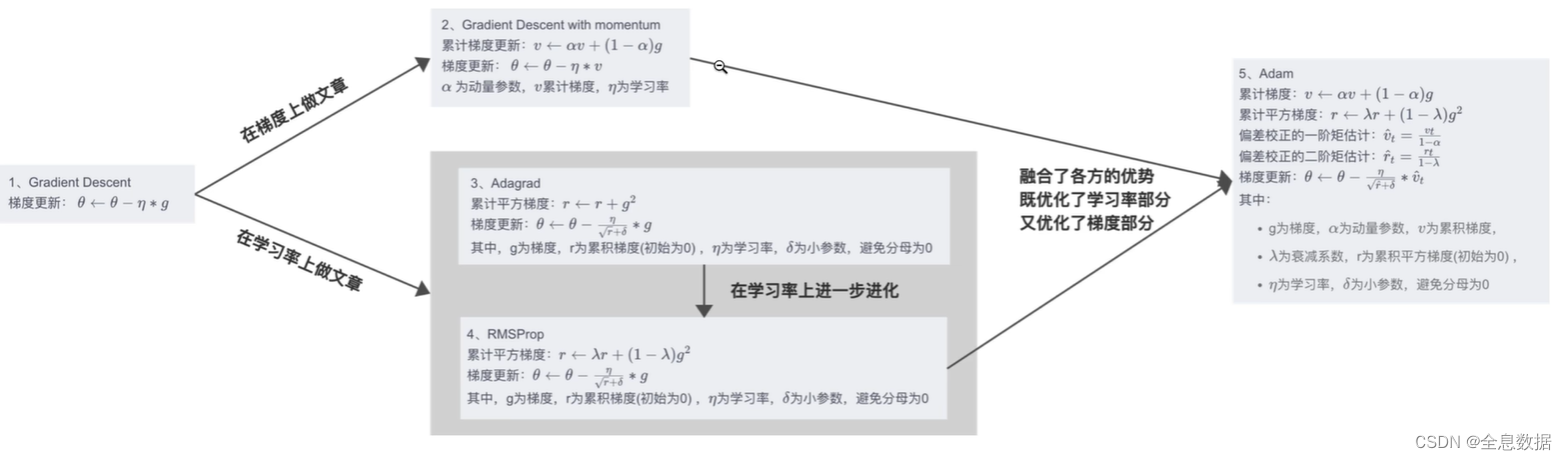
全称:Root Mean Square Propogation / Adaptive Delta
目的:解决AdaGrad过早收敛的问题;

结合了SGDM和AdaDelta


参考:
1、哔站视频
地址:海南省海口市玉沙路58号 电话:0898-88889999 手机:13988889999
Copyright © 2012-2018 首页-四方娱乐-注册登录站 ICP备案编:琼ICP备88889999号






